How to Sync Data Between Applications with Reliable Two-Way Sync
A practical guide to syncing data between applications with real-time, two-way sync: how it works, the common pitfalls, and how to keep your systems consistent.
- Author
- Ruben Burdin · Founder & CEO
- Published
- April 5, 2025
- Read time
- 7 min read
In the modern enterprise, operational efficiency is directly tied to data integrity. Teams rely on a suite of specialized applications, CRMs for sales, ERPs for finance, and databases for custom applications. While this best-of-breed approach provides powerful tools for each function, it inevitably creates disconnected data. When customer, product, or financial data exists in multiple, disconnected systems, the result is operational friction, manual reconciliation errors, and strategic decisions based on outdated information.
Traditional methods of data integration, such as nightly batch jobs or simple one-way data pushes, are often insufficient. They introduce latency, are prone to failure, and cannot provide the single, consistent view of data required for real-time operations. A reliable solution to this technical challenge is true bi-directional, or two-way, data synchronization.
What is Two-Way Data Synchronization?
Two-way data synchronization, also known as bi-directional sync, is a process that ensures data in two or more systems remains identical. When a change is made in one application, it is automatically and promptly reflected in the connected application, and vice-versa. This creates a single, unified source of truth that is shared, editable, and consistently up-to-date across all systems.
Unlike one-way sync, which only pushes data from a source to a destination, two-way sync allows for a dynamic and interactive data flow. This is critical for operational systems where users in different departments, such as sales updating a CRM and finance updating an ERP, need their changes to propagate across the organization without manual intervention or delay.
The Technical Challenges of Implementing Reliable Two-Way Sync
Achieving reliable two-way synchronization is a complex engineering problem. A reliable solution must overcome several significant technical hurdles that often cause custom-coded scripts or generic integration platforms to fail.
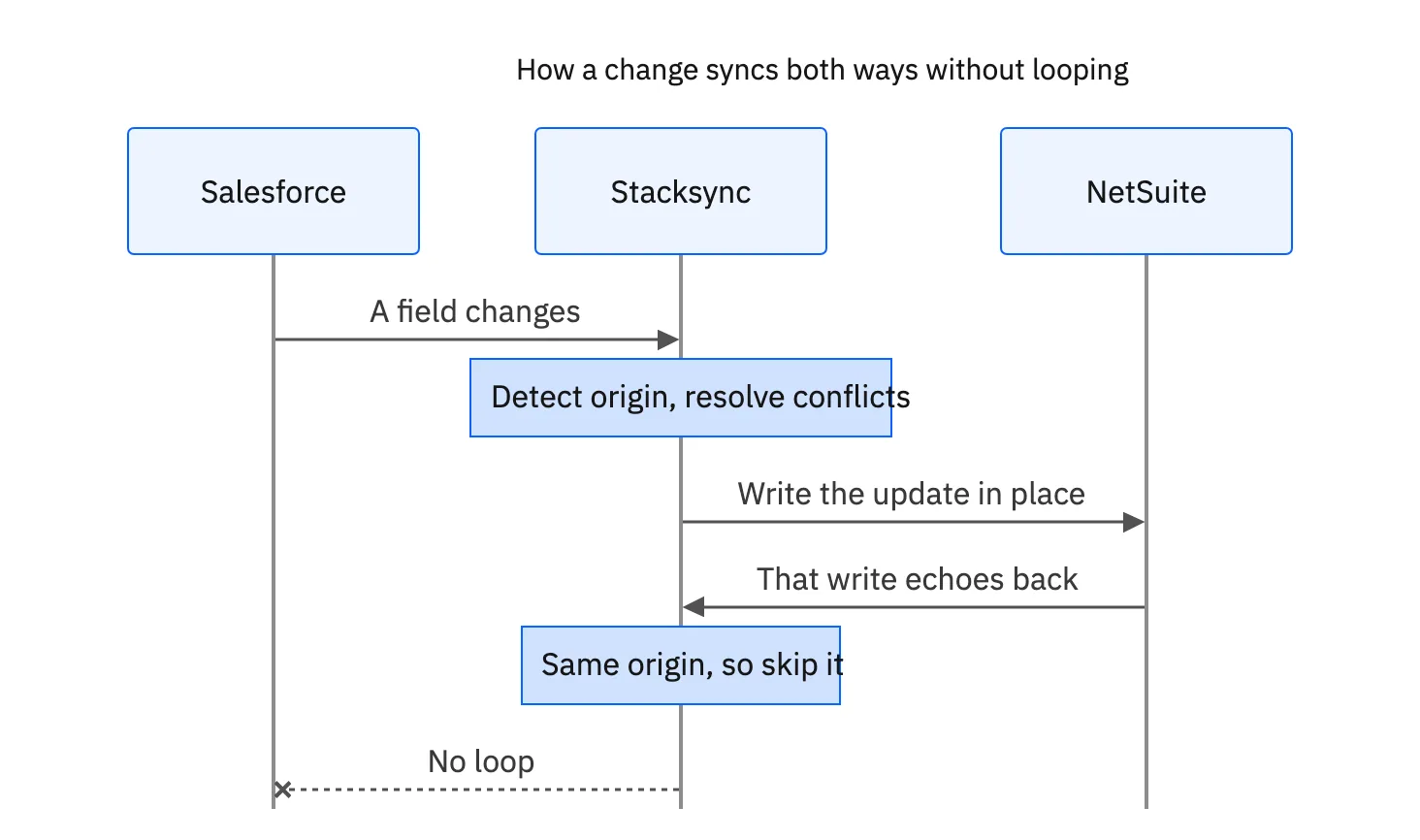
Conflict Resolution: The most critical challenge is handling simultaneous updates to the same data record in both systems. A naive implementation can lead to data loss or corruption. A reliable system requires a sophisticated conflict resolution mechanism, such as "last update wins" or a predefined system of record, to ensure data integrity is always maintained.
Latency: For operational use cases, data must be synced in real-time. Relying on periodic polling (e.g., checking for changes every few minutes) is inefficient and introduces unacceptable delays. A high-performance sync technology should be event-driven, capable of capturing and propagating changes with minimal latency.
API and Schema Complexity: Every application has a unique API with its own rate limits, authentication protocols, and data structures. Furthermore, systems like Salesforce and NetSuite have vastly different data models. A sync tool must intelligently manage API usage to avoid hitting rate limits and seamlessly map fields between disparate schemas, including both standard and custom objects.
Reliability and Error Handling: When an API is temporarily unavailable or a data validation rule fails, a reliable sync platform must have automated retry logic, dead-letter queues, and comprehensive monitoring dashboards to detect, alert, and manage issues without requiring constant manual oversight or risking data loss.
Scalability: A synchronization solution must perform reliably whether it is handling a few thousand records or tens of millions. It needs to scale effortlessly as data volumes and transaction velocity increase, a common failure point for brittle, in-house scripts.
Common Approaches to Data Synchronization (And Their Limitations)
Organizations typically attempt to solve data synchronization with one of several methods, each with significant technical drawbacks.
| Method | Description | Limitations |
|---|---|---|
| Custom Code / In-house Scripts | Engineers write custom scripts using application APIs to move data between systems. | Extremely resource-intensive to build and maintain. Brittle, prone to silent failures, and difficult to scale. Lacks sophisticated error handling and conflict resolution. |
| Generic iPaaS Platforms | Large integration platforms (Integration Platform as a Service) that offer a wide range of connectors. | Often not truly bi-directional; they simulate it with two separate one-way syncs, which can create race conditions and data conflicts. Can be overly complex and expensive for pure-play sync use cases. |
| One-Way ETL/ELT Tools | Tools designed to extract data from source systems and load it into a data warehouse for analytics. | By definition, not bi-directional. Data in the destination is read-only, making it unsuitable for operational workflows where data must be updated from multiple endpoints. |
| Point-to-Point Connectors | Simple, pre-built connectors that sync data between two specific applications. | Not scalable. Creates a tangled web of individual integrations that are difficult to manage, monitor, and maintain as the number of applications grows. |
These approaches often fail because they are not built for the specific, demanding requirements of real-time, bi-directional data synchronization.
The Solution: A Dedicated Platform for Two-Way Sync
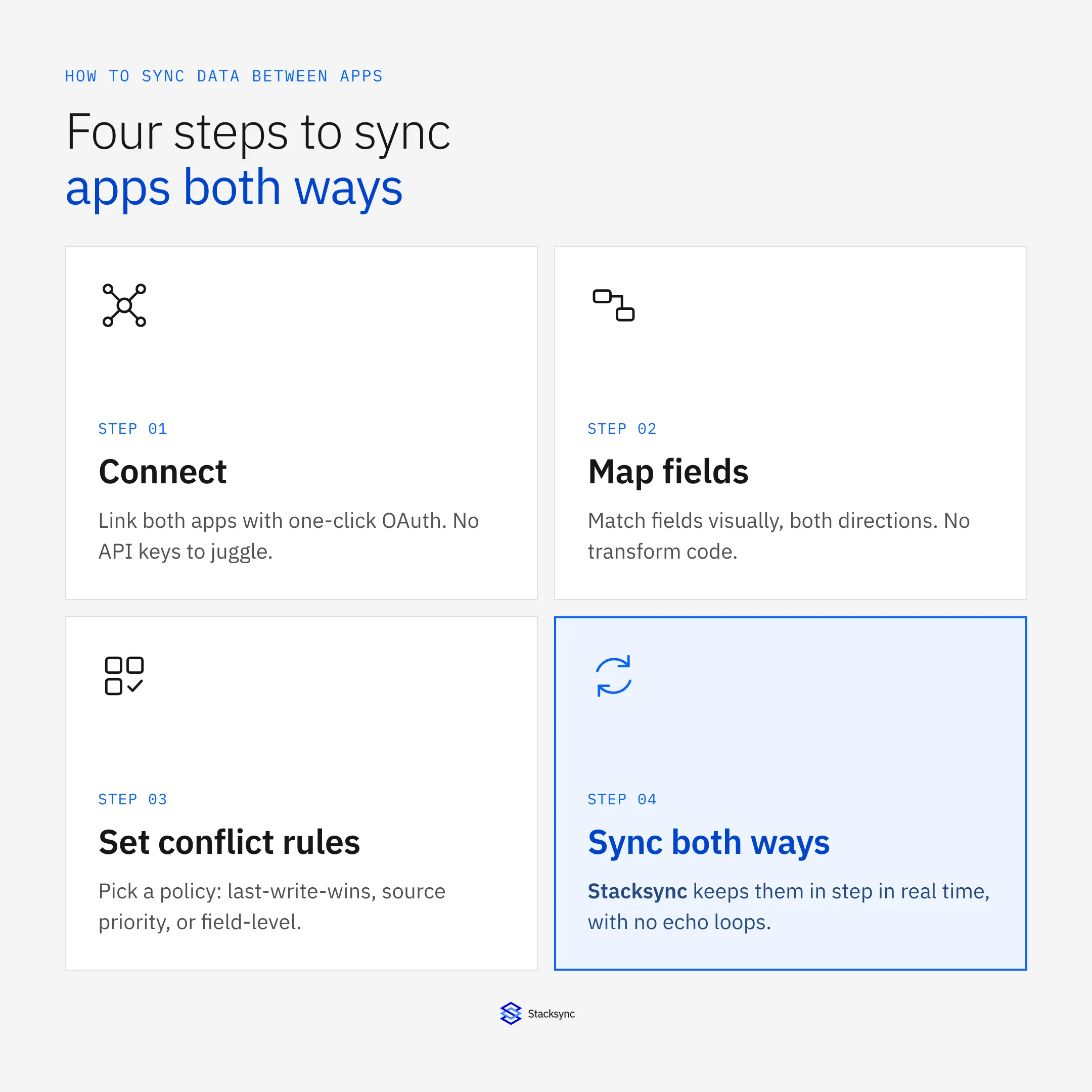
The most efficient and reliable way to sync data between applications is to use a platform engineered specifically for real-time, bi-directional synchronization. These platforms abstract away the underlying complexity, providing a reliable, scalable, and manageable solution.
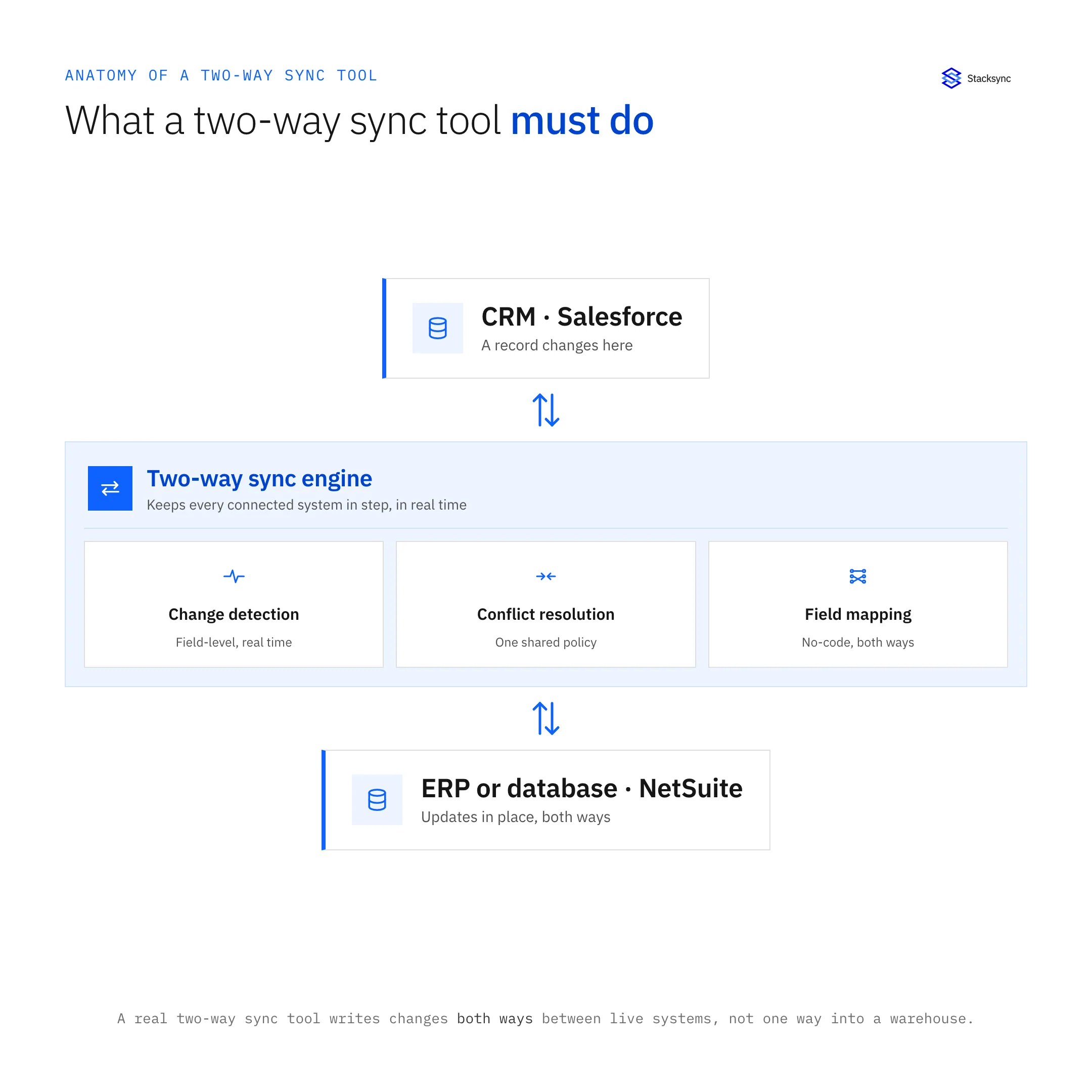
A dedicated bi-directional sync platform is designed to solve the core technical challenges that cause other methods to fail. It provides a resilient infrastructure for synchronizing data between CRMs, ERPs, and databases, ensuring data consistency across the enterprise.
Key features of a dedicated platform include:
True Bi-Directionality with Conflict Resolution: Architected from the ground up for genuine two-way data flow, with built-in, configurable conflict resolution to handle simultaneous updates gracefully and prevent data corruption.
Real-Time, Event-Driven Architecture: By leveraging an event-driven architecture, these platforms can achieve low-latency synchronization, reacting quickly to data changes and ensuring that all connected systems reflect the most current information for mission-critical operations.
Automated Reliability and Monitoring: Enterprise-grade reliability with features like automated retries, advanced logging, and issue management dashboards. Proactive alerting via communication channels ensures that any sync issues are identified and resolved immediately.
Effortless Scalability and API Management: Designed to handle enterprise scale, supporting large volumes of records and executions per minute. Smart API management systems automatically handle the complexities of rate limits, pagination, and authentication for each connected application, ensuring smooth performance without manual tuning.
Simplified Complexity: With a no-code or low-code setup, teams can establish complex bi-directional syncs quickly. The platform automatically maps schemas and supports both standard and custom objects and fields, eliminating the need for extensive custom development.

Key Use Cases for Two-Way Data Synchronization
Implementing a reliable two-way sync platform unlocks powerful operational capabilities and efficiencies across the organization.
CRM and Database Sync: Allow developers to interact with CRM data using the power and familiarity of SQL in a database like PostgreSQL or MySQL. Any changes made in the database are instantly synced back to the CRM, and vice-versa.
ERP and CRM Integration: Create a single, unified view of the customer journey. When a sales representative closes a deal in the CRM, an order can be automatically created in the ERP. When finance issues an invoice from the ERP, the customer record in the CRM is updated, giving the entire organization a 360-degree view.
Real-Time Database Replication: Reliably replicate data between geographically distributed servers or from a production OLTP database to an analytical database. This ensures high availability and provides analysts with up-to-the-minute data without impacting the performance of the production system.
Cross-Platform Workflow Automation: Use data changes in one system to trigger complex workflows in another. For example, a change in a customer's support ticket status in a helpdesk system could trigger an update in a CRM and a notification in a project management tool, all orchestrated through the sync platform.
Keep Your Operations Running on Consistent Data
Disconnected data is a fundamental barrier to operational excellence. They force teams into inefficient manual processes and compromise the integrity of the data that drives the business. Attempting to solve this with brittle custom scripts or ill-suited generic tools only trades one problem for another, burdening engineering teams with the maintenance of "dirty data plumbing."
A dedicated, reliable two-way sync platform is a reliable solution. By abstracting away the immense complexity of real-time data integration, these platforms provide a scalable, resilient, and secure foundation for all operational data. This lets technical teams to stop managing infrastructure and start building competitive advantages, confident that their data is consistent, accurate, and always available across every application.

FAQ
Frequently asked questions
Related articles